
В одній з попередніх статей ми детально розповідали, як можна створювати відмовостійке рішення, використовуючи одну з функцій систем зберігання даних HPE Peer Persistence, яке реалізовано на HPE Alletra 5000/6000 і HPE Nimble. Тобто це закінчене рішення, призначене для додатків, яким необхідно забезпечити показники відмовостійкості, що прагнуть до нуля: цільова точка відновлення (RPO) і цільовий час відновлення (RTO), використовуючи при цьому синхронну реплікацію з автоматичним перемиканням (automatic switchover). Це все відмінно працює і просто налаштовується.
Але є у компанії HPE і такі системи зберігання, як HPE Primera і HPE Alletra 9000 і як у цього модельного ряду йдуть справи з подібним відмовостійким рішенням? Виявляється, таке рішення є, воно навіть ще цікавіше і називається - HPE Active Peer Persistence.
На відміну від класичного рішення HPE Peer Persistence, яке дає змогу тільки первинній системі зберігання в рішенні обслуговувати введення-виведення для виділених томів (virtual volume) у групі віддаленого копіювання (remote copy group), налаштованій для синхронної реплікації (synchronous replication), то HPE Active Peer Persistence дає змогу використовувати як первинну, так і вторинну системи зберігання у HPE Active Peer Persistence Remote Copy для обслуговування запитів вводу-виводу застосунків для віртуальних машин. Тобто HPE Active Peer Persistence дає змогу зробити рішення ще цікавішим і вигіднішим і яке балансуватиме навантаження серверного введення-виведення між двома системами зберігання для віртуальних томів. Цей сервіс також підтримує загальні кластерні рішення для віртуальних томів (virtual volume), які потребують максимальної доступності, даючи змогу серверам у кластері надсилати введення-виведення в обидві системи зберігання.
Підключення серверів до обох систем зберігання в рішенні є обов'язковим і гарантує прозоре відновлення після збою. Ця конфігурація також гарантує, що сервери, як і раніше, матимуть доступ до своїх даних з нульовим RPO і нульовим RTO для широкого спектра потенційних збоїв.
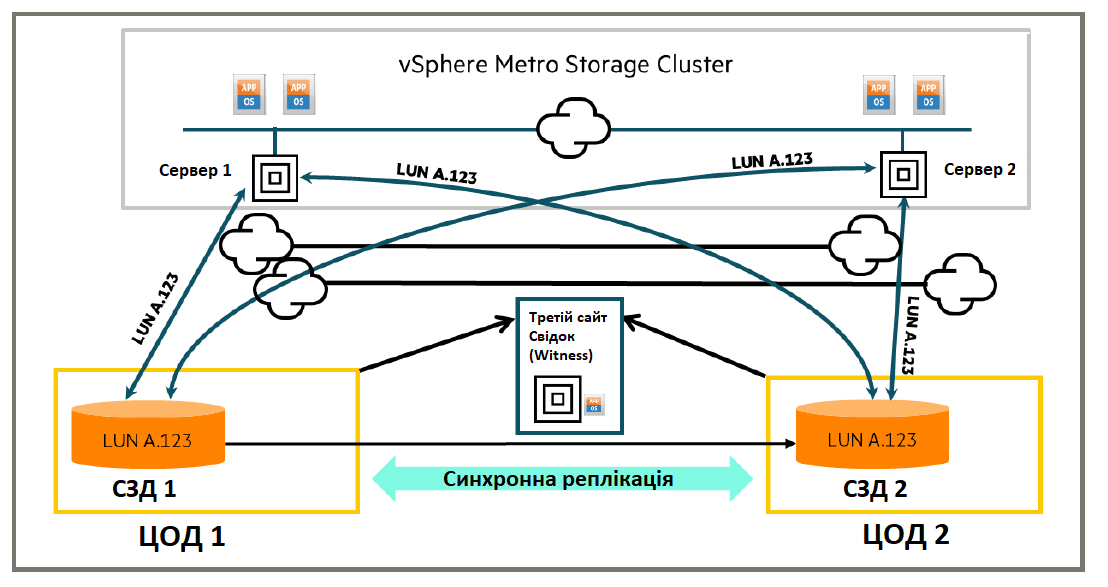
При цьому всі шляхи до обох систем зберігання активні для всіх серверів, що використовують групу HPE Active Peer Persistence. Сервер може надсилати запити введення-виведення в будь-яку із систем зберігання, але бажано, щоб сервери надсилали введення-виведення тільки в ту систему, до якої вони перебувають у безпосередній близькості, а не надсилали введення-виведення в систему на віддалений майданчик, водночас маючи додаткову затримку («довгий неоптимізований шлях»). Це досягається шляхом зазначення того, чи є шлях сервера до системи зберігання «оптимізованим» шляхом (найменша затримка) або «неоптимізованим» шляхом (вища затримка). Передбачається, що сервер буде використовувати оптимізовані шляхи; якщо оптимізовані шляхи недоступні, то в цьому випадку він буде використовувати свої неоптимізовані шляхи. Терміни «оптимізований» і «неоптимізований» щодо шляхів сервера до систем зберігання належить до станів шляху ALUA (Asymmetric Logical Unit Access), встановлених на шляху.
Для HPE Active Peer Persistence стан шляху ALUA такий:
- Активний оптимізований ALUA: активний шлях, кращий для запитів введення-виведення сервера. Очікується, що шлях буде використовуватися сервером, якщо він доступний. Він повинен мати найменшу затримку від сервера до системи зберігання.
- ALUA активний неоптимізований: активний шлях, який є альтернативним шляхом для запитів введення-виведення сервера. Цей шлях слід використовувати тільки в тому разі, якщо активні оптимізовані шляхи недоступні. Активні неоптимізовані шляхи зазвичай мають значно більшу затримку від сервера і до системи зберігання.
- ALUA недоступний: шлях недоступний, і серверне введення-виведення не може бути надіслано шляхом. Шляхи до вторинної системи зберігання стають недоступними, якщо групу віддаленого копіювання зупинено або будь-які віртуальні томи в групі не синхронізовано.
Адміністратор систем зберігання сам зможе визначити, чи є шлях оптимізованим або неоптимізованим, при налаштуванні HPE Active Peer Persistence. Це дає змогу серверам, які розташовані в різних центрах оброблення даних (ЦОД1 і ЦОД2), але спільно використовують віртуальні томи в групі віддаленого копіювання (наприклад, для vSphere Metro Storage Cluster), надсилати ввід-вивід тільки в систему зберігання, до якої вони перебувають у безпосередній близькості. Це так само дає змогу уникнути додаткової затримки, пов'язаної з відправленням операцій введення-виведення на віддалену систему зберігання, як це може статися з класичним одноранговим збереженням. Незалежно від того, чи знаходиться сервер поруч з первинною системою або вторинною для HPE Active Peer Persistence, очікується, що час відгуку вводу-виводу групи віддаленого копіювання (читання і запис) буде однаковим для вводу-виводу, який надсилається в локальну систему зберігання.
Як HPE Active Peer Persistence, так і класична HPE Peer Persistence призначені для прозорого відновлення (з показниками RPO = 0 і RTO = 0) після збоїв систем зберігання. Як HPE Active Peer Persistence, так і класична HPE Peer Persistence прозоро відновлюються після таких сценаріїв збоїв:
- Збій системи зберігання даних: якщо система зберігання в конфігурації HPE Active Peer Persistence дає збій, вціліла система за необхідності бере на себе управління групою віддаленого копіювання і обслуговує всі операції введення-виведення.
- Збій каналу реплікації: первинна система зберігання продовжує обслуговувати введення-виведення. Ніякі дані не реплікуються в/з вторинної системи зберігання. Під час використання HPE Active Peer Persistence шляхи ALUA до вторинної системи зберігання стають недоступними, а всі операції введення-виведення хоста спрямовують у первинну систему зберігання для групи HPE Active Peer Persistence.
На додаток до цих збоїв HPE Active Peer Persistence прозоро відновлюється після збоїв, від яких не відновлюється класичне рішення HPE Peer Persistence:
- Вимкнення фізичного сервера (сервер втрачає всі під'єднання до своєї оптимізованої системи зберігання): сервер, який втрачає під'єднання до своїх активних оптимізованих шляхів, використовуватиме свої активні неоптимізовані шляхи.
- Перезавантаження/відключення основної системи зберігання: відбувається автоматичний прозорий збій (automatic transparent failure), і вторинна система зберігання стає основною для всіх груп HPE Active Peer Persistence Remote Copy.
Універсальність цих рішень полягає ще в тому, що можна налаштувати перемикання цих технологій з HPE Peer Persistence в HPE Active Peer Persistence і навпаки без перезавантаження систем зберігання та переривання роботи застосунків. Так само одночасно на системах зберігання можна використовувати як HPE Active Peer Persistence, так і HPE Peer Persistence.
HPE Active Peer Persistence у системах зберігання HPE Alletra 9000 і HPE Primera - це значне поліпшення порівняно з класичним продуктом HPE Peer Persistence. Завдяки можливості обслуговувати введення-виведення сервера для томів у групі віддаленого копіювання з обох систем зберігання в рішенні HPE Peer Persistence, HPE Active Peer Persistence забезпечує значне зниження загальної затримки вводу-виводу для кластерних файлових систем, різних баз даних і різних додатків, порівнюючи з класичним HPE Peer Persistence. Завдяки цим перевагам, а також кращій доступності та простоті управління порівняно з класичним рішенням HPE Peer Persistence, ми рекомендуємо розгортати та використовувати саме HPE Active Peer Persistence.
Автор статті - Михайло Федосєєв, архітектор інфраструктурних рішень Lantec.